4bit PQ reading & implementing
4bit PQ 实现笔记:为什么它理论上能比 8bit PQ 更快,Quick ADC 依赖的 code 转置和 SIMD lookup,以及实际实现里 distance quantization 的取舍。

systems notes / paper reading / build logs
Notes on vector databases, query engines, operating systems, and the engineering details that decide whether an idea actually ships.
latest
4bit PQ 实现笔记:为什么它理论上能比 8bit PQ 更快,Quick ADC 依赖的 code 转置和 SIMD lookup,以及实际实现里 distance quantization 的取舍。
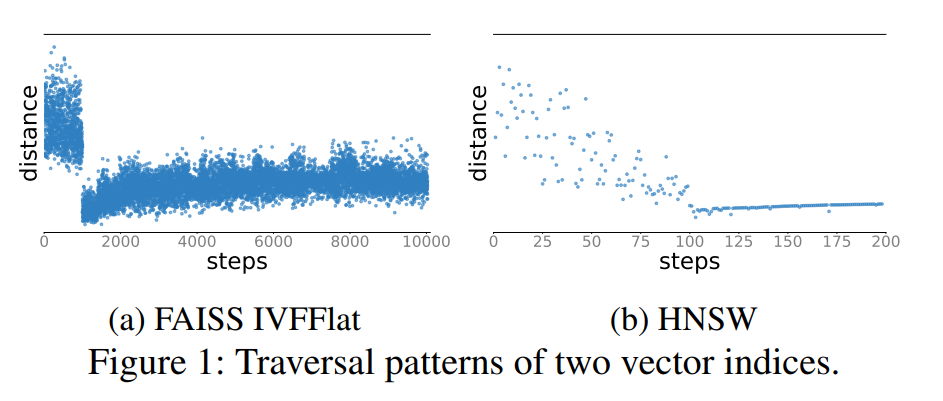
TL;DR这篇论文首先是引入了 relaxed monotonicity 的概念,然后基于对向量索引的 relaxed monotonicity 性质的观察:ANN 的检索过程中会有两个阶段,第一阶段中会快速向目标向量靠近,第二阶段向量整体上会逐渐远离目标向量。论文中给出了判定查询已经进入第二阶段的
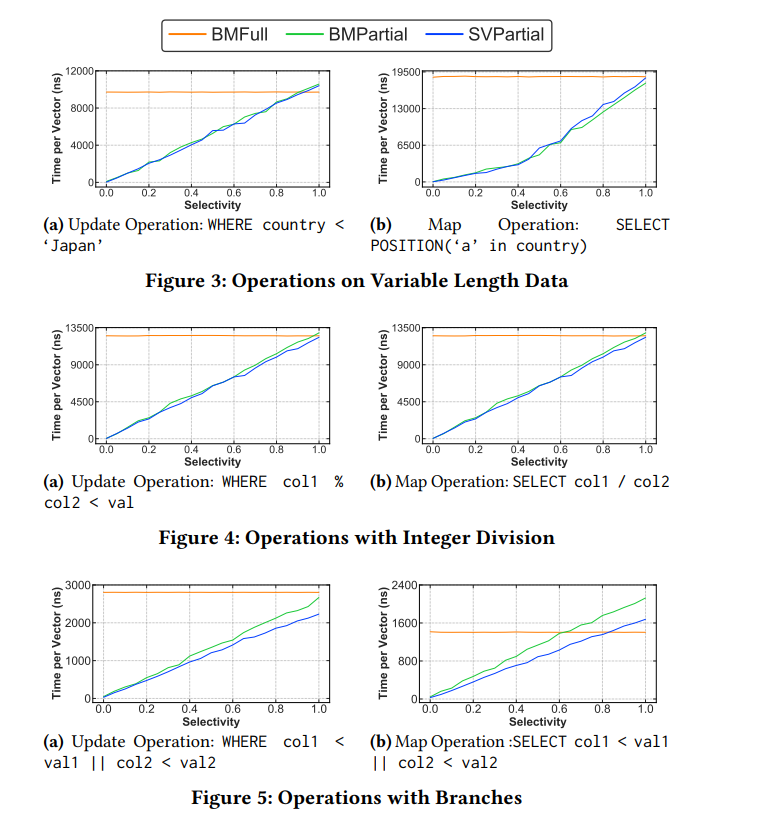
目前向量化执行引擎在执行过滤操作时会有这样一些策略:用一个 bitset 来标记哪些数据是被过滤选中的用一个 vector 存储被命中的数据的下标将命中的数据复制后传递到下一个算子这篇文章主要讨论了前两种,文章里称之为 Bitmap(BM) 和 Seleteced Vector (SV)。第三种策略
前段时间购置了一个显示器,规格是 2K@240Hz,用起来之后感觉比 144Hz 流畅很多,但是很快我就发现这个显示器有一个问题。 当我进行全屏游戏的时候,如果这个时候切回到桌面,显示器会短暂黑屏一段时间,并且弹出 OSD 显示显示器目前的状态。因为我需要经常切出游戏做别的事情,这个黑屏带来的体验太...
Linux 的 swap,cache 与 mmap众所周知,Milvus 需要把数据全部加载到内存中后才能执行查询。这会对 Milvus 中的查询节点有很高的内存需求,但对于离线场景,用户对查询性能不敏感,可以接受性能降级。这里常规的解决方案是做一个 buffer pool,查询时按需地的将数据加载
MIT 6.824 Lab2 Raft最近突然想再刷一下 6.824,想试试自己现在做会不会容易得多。上次做已经是大二的时候了,对之前的代码已经毫无记忆了(而且也写得不咋样)。因为 Lab1 没什么难度,我这次就跳过了,直接从 Lab2 开始。Lab2 是实现 Raft,在继续看下面的内容之前,你至
No matching posts.
selected