TL;DR
This paper introduces the concept of relaxed monotonicity. It observes that ANN search over vector indexes usually has two phases. In the first phase, the search quickly moves closer to the query vector. In the second phase, candidates as a whole gradually move farther away from the query. The paper gives a way to detect when the search has entered the second phase. Once the search has entered that phase and already has k results, it can stop early and improve performance.
The powerful part is not just early termination. Once we know the search has entered the second phase, we can continue the search and produce more vectors in roughly increasing distance order. This breaks out of the traditional top-k-only ANN interface and gives us a streaming result primitive.
With that streaming primitive, scalar filtering, hybrid scoring, multi-vector queries, and even vector joins can be optimized significantly.
Relaxed Monotonicity
From the perspective of monotonicity, an index search starts from some point and keeps looking for data points that are closer to the target. Vector indexes do not have strict monotonicity, but the HNSW example in the paper illustrates the pattern:
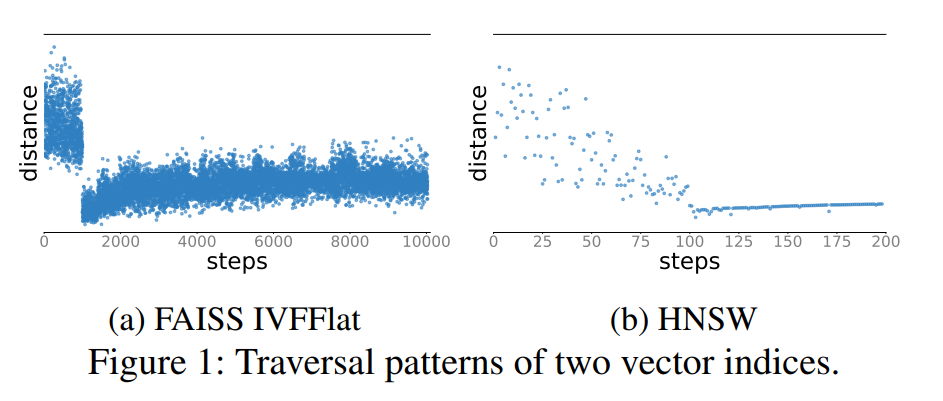
The search process can be divided into two phases. Early in the query, traversal in the upper layers quickly moves the candidate set closer to the target. Later, the candidate set has mostly converged, and continuing traversal rarely finds significantly better results.
If we can detect this turning point, we can optimize ANN search: after entering the second phase, once we have K results we can stop. The paper gives this intuition:
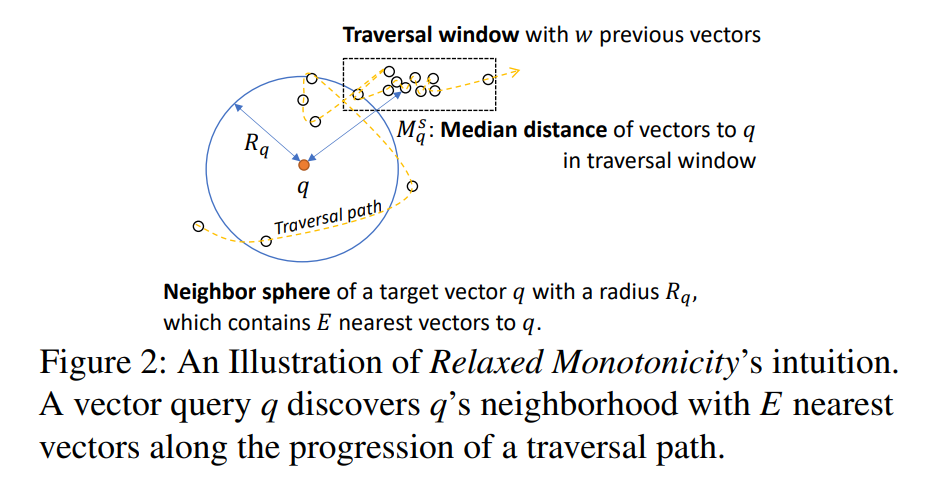
Here q is the query vector, R_q is the neighborhood radius, and M_q^s is the median distance from the current traversal window to q. The intuition is that if M_q^s >= R_q, the search may have entered the second phase.
This is not a rigorous guarantee. For example, if the query is top-2 and w = 1, the method above may decide that the search has entered the second phase even when recall is 0. In an HNSW-style implementation, the coarse-grained graph does not use this check and is always searched. The check is used only in the fine-grained graph. A larger w can also improve recall.
Relaxed monotonicity provides a very useful primitive. The algorithm only needs to run until it reaches the second phase. It can then save the traversal state and keep producing results, effectively exposing a streaming query primitive.
Scenario Optimizations
The streaming primitive enabled by relaxed monotonicity can improve several workloads.
Scalar Filter plus Vector Search
Scalar filtering with vector search is a basic feature in vector databases. Because ANN indexes usually expose only a batched top-k interface, current systems mainly use two strategies:
- Pre-filtering: run scalar filtering first, generate a bitmap, and then use the bitmap to filter vectors during ANN search.
- Post-filtering: query for K' results where K' is larger than K, then apply the scalar filter to the returned result set.
Counterintuitively, pre-filtering can slow down ANN indexes because the search may need to traverse more vectors to find enough matching results. Lower selectivity usually means worse performance. Post-filtering has the obvious problem that K' is hard to choose. We do not know in advance how many candidates will be filtered out. If the final result set is too small, the system may have to retry with an even larger K'', which can be very expensive.
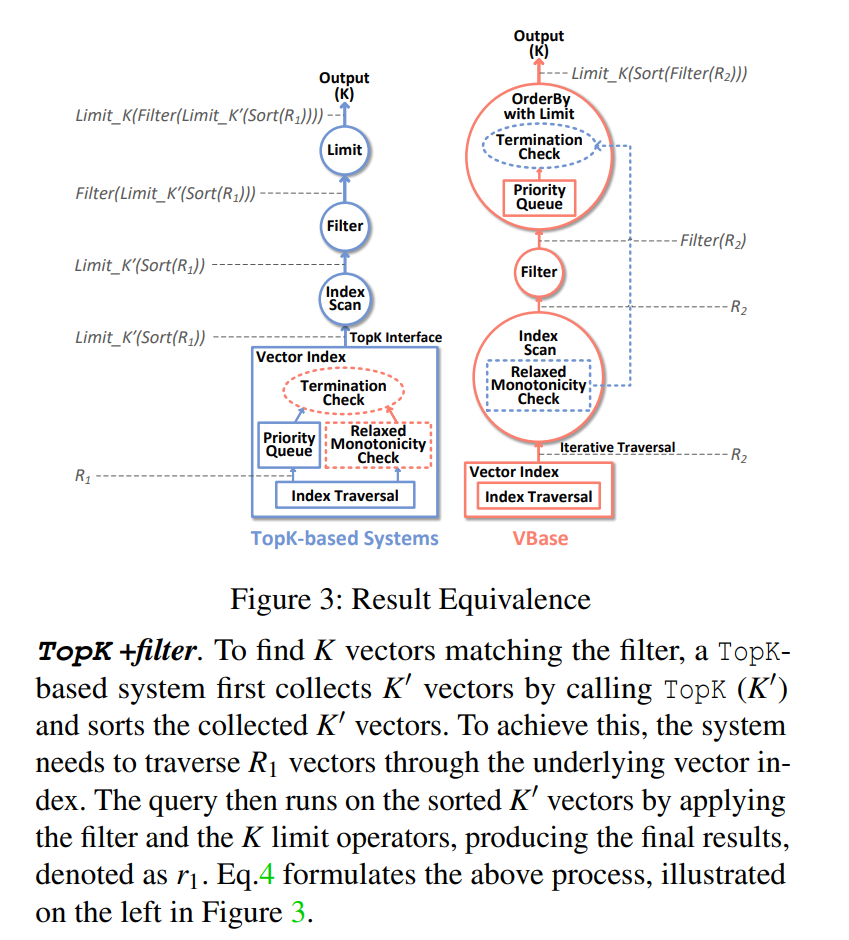
With the streaming primitive, scalar filtering plus vector search becomes simple. We continuously pull results from the index and apply the scalar filter. Once the final result set reaches K, we stop. Performance is equivalent to post-filtering with the optimal K~.
Multi-vector Queries
A multi-vector query searches over multiple vector columns and aggregates the scores to select the final top-k results.
I stopped here for now. I need to learn NRA first before continuing.