Vectorized execution engines commonly represent filters with a few strategies:
- Use a bitset to mark selected rows.
- Use a vector to store the indexes of selected rows.
- Copy selected rows and pass the copied data to the next operator.
This paper mainly discusses the first two strategies, called Bitmap (BM) and Selection Vector (SV). Some systems also use the third strategy. The paper does not discuss it, but I have seen DataFusion use it, so I will return to it at the end.
Filter Representation
For BM and SV, there are three main strategies:
- BMFull: always process all rows. Values for unselected rows are undefined. The advantage is that it can fully exploit vectorization.
- BMPartial: process only selected rows, but it still needs to scan all positions and cannot fully use vectorization.
- SVPartial: scan only selected indexes, but it cannot fully use vectorization either.
The Manual suffix in the paper means SIMD is implemented manually, using AVX-512, instead of relying on compiler optimization. SVManual can still use vectorization to some extent.
Cost Model
The paper estimates computation cost with this formula:
R = N * (I + O)N is the number of rows, I is the per-iteration cost, O is the per-row processing cost, and R is the estimated runtime.
The cost of each strategy is determined by these three variables. I is fixed for a given strategy. O and N depend on filter selectivity, and O is also strongly affected by the data type being processed.
BMFull is special because all three variables are fixed. From this model, we can compare strategies under different filter rates.
Comparison Scenarios
The paper defines two primitives:
- Update: operations that update the selected set, such as where a < b.
- Map: operations that transform data, such as select a + b.
The experiments mainly compare these two kinds of primitives.
No Data Parallelism
For string processing, integer division, and similar workloads, the CPU cannot efficiently vectorize multiple rows. In these cases, the per-row processing cost is higher.
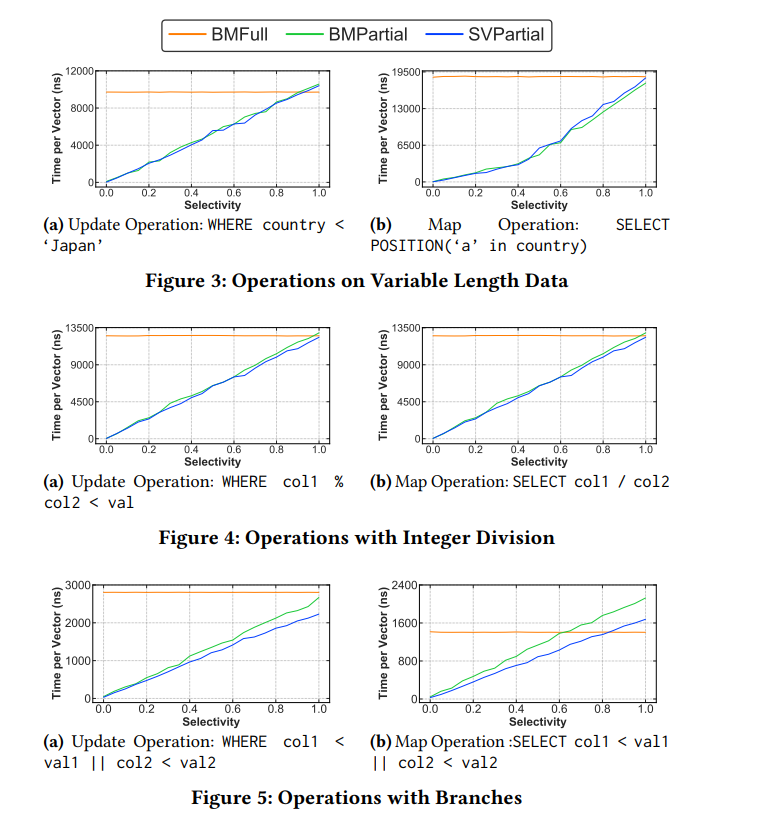
BMPartial and SVPartial perform very similarly. BMPartial has higher iteration overhead, so SVPartial is usually better. In this scenario, SVPartial is the best strategy.
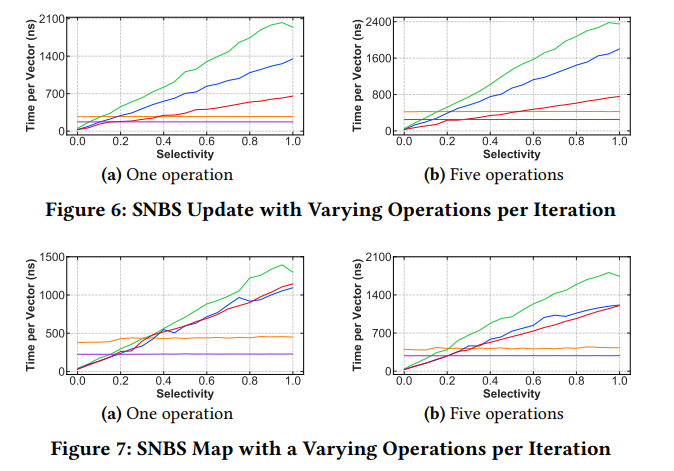
Inefficient Data Parallelism
For logical AND and OR operations, SISD may execute less code because of short-circuiting. SIMD does not necessarily cost less than SISD here.
SVPartial is still best overall. BMFull only has an advantage at high selectivity, mainly for the Map primitive.
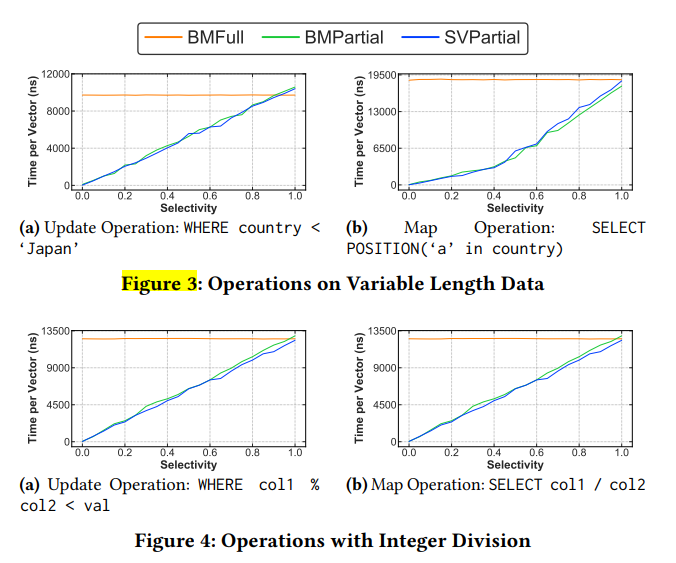
Data Parallelism
For ordinary numeric operations, SIMD can be used effectively.
In this case, partial strategies only win at low selectivity, below roughly 0.2. At higher selectivity, BMFull wins because it benefits from vectorization.
The paper also studies how the number of arithmetic instructions affects the threshold:
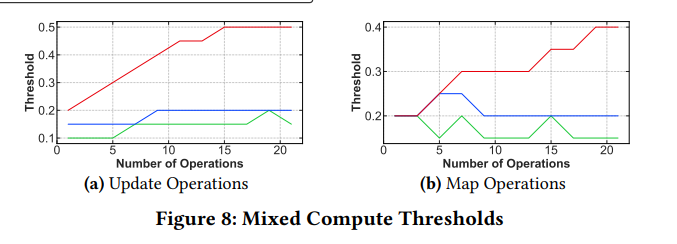
The threshold is quite stable, around 0.2.
TPC-H Tests
The paper proposes a hybrid strategy: use BMFull, or BMFullManual, when selectivity is above 0.2, and use SVManual when selectivity is low. It then compares this hybrid strategy with the single strategies.
Here is one result:
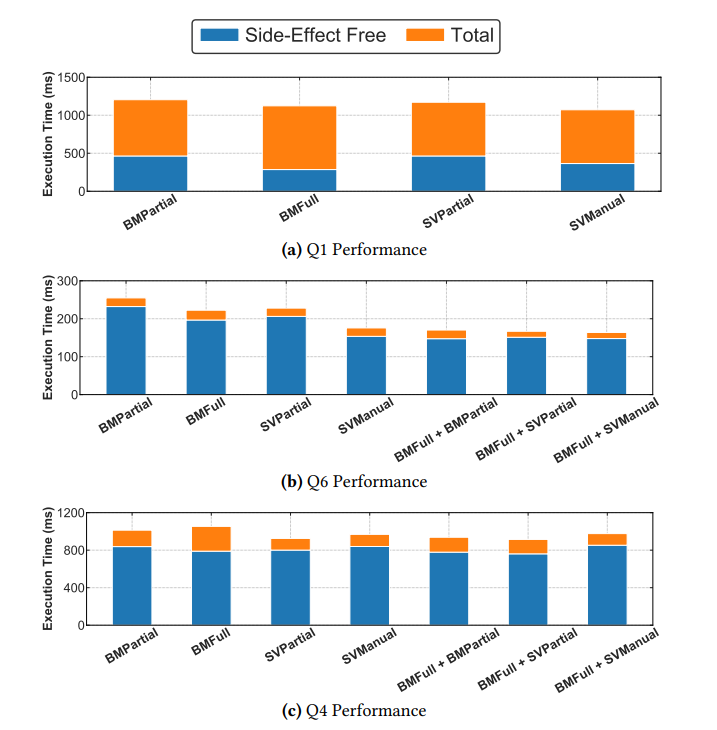
Q1: High-selectivity Data Parallelism
This query has a high-selectivity filter, around 0.95, followed by an aggregation with side effects, which means it cannot be data-parallel.
During filtering, BMFull is 1.6x faster than SVPartial and 1.3x faster than SVManual. But the query time is dominated by the final aggregation, so the end-to-end runtime is similar. One detail is worth noting: BMPartial and BMFull are equivalent for the final aggregation, but BMFull spends more time overall because AVX-512 during filtering causes CPU downclocking.
Q6: Mixed-selectivity Data Parallelism
In this test, the second filter reduces selectivity to 0.15. This triggers the hybrid strategy to switch representations, making it a good case for comparing hybrid performance.
The hybrid strategy is faster than every single strategy. However, BMFull plus SVManual is slower than BMFull plus BMPartial, even though SVManual alone is better than BMPartial. The reason is conversion overhead from bitmap to selection vector.
Because final selectivity is low, most query time is spent in earlier SLDP operations, so AVX-512 downclocking does not hurt the whole query much.
Q4: Low-selectivity and Weak Data Parallelism
This test also has low selectivity and cannot fully exploit SIMD. BMFull plus SVPartial is the best strategy, but it is not much better than BMFull plus BMPartial.
Conclusion
From the paper's results, a hybrid strategy can improve performance by around 30%. When designing the strategy, one should account for the query type and for effects such as AVX-512 downclocking. Personally, I would choose BMFull plus BMPartial. It is the simplest to implement and is optimal in many cases.
Finally, about the copy-selected-data strategy mentioned at the beginning: using the same analysis, this strategy should beat SVPartial when selectivity is low and the operation is data-parallel. It adds copy overhead, but it lets the engine use vectorization more fully. DataFusion is not slow with this approach. For high-selectivity filters, though, it should perform poorly, and it should also be bad for string processing.
The most uncomfortable part is that this representation cannot easily convert to or from bitmap and selection-vector formats, unless the data carries an extra index column, which adds its own overhead. That leaves little flexibility or room for future optimization.